��ģ����ҵԽ��Խ���֡����⣬��˹��ΪTwitter����1���GPU�ﱸ��ģ����Ŀ������ѷ����Ͷ�ʴ�������ģ�ͺ�����ʽ AI��OpenAI�Ƴ���ChatGPT iOS�汾�����ڣ��ٶȷ�������һ�ԡ������ͨ��ǧ�ʣ���С���������ġ��ƿ��ܵȡ��б������Ĵ�ҵ���ܲ�������
��������ѧϰ���ԣ���ģ����AI����֪��������һ��¥������ʵ����ν�ġ�����ӿ�֡���������ChatGPT��AutoGPT��AIGC������Ӧ�ã���AIȫ����빤ҵ���������Ρ�Ӣΰ�ﴴʼ�ˡ�CEO����ѫ˵��AI�ġ�iPhoneʱ�̡����١��ڼ������ĵġ�iPhoneʱ�̡�����ҵȱʲô��
��ģ��ս��AI���ż�һ�±����
�������AI��ҵ�Լ���������ҵ��̬��ͬ����ģ�ͳ�Ϊ��ͷ����ҡ�����Ϸ����Ծ�����Ҫô�Ǵ�Ҫô�����ʽ�ӳֵġ��б�������ҵ�ߣ����ݸ���ҵ�ߡ���δ���֡�
��ģ�;��С��������ݡ������㷨�����������������������������κ���ҵ������ͷ��˵������һ����ģ�Ͷ�����һ���������飬��Ҫ�ռ��������ݡ���Ҫ��������������Ҫ���д����з�����Ǯ��ʱ�䡢����Ͷ��ͬ������������ChatGPT�Ǵ�ҵ��˾OpenAI���ģ���ҹ�˾��2015�������͵�����8�꣬�������Ⱦ�ͷ/����֧�֣��ײ�Ӳ��Ͷ��ߴ�10����Ԫ���ϣ�ÿ��ѵ�����ĵĵ����㹻3000����˹������ÿ����20��Ӣ�
�������������ô�ģ���з��ż����ߣ����κμ�����̬Ҫ�����ٶ��벻����ữ���¡��ƶ�������������Դ����iOS�Ͱ��ij��֣���Ҳ�벻��Ӧ���г��������ߵĴ��¡�ͬ������ģ���ϡ���������Ӧ��Ҳ���ÿ������������壬��AI��ģ��Ϊ���п����ߣ����������̡���ҵ����֯�����忪���ߵȣ����ã��Ǽ��ٴ�ģ�Ͳ�ҵ��չ�Ĺؼ���
����Ŀǰ����ģ�ͻ����ڡ�ֻ�������������ˡ��ĽΣ��Ĵ�ģ�����ڿ��ţ�����Ҫʹ�����нϸߵ��˲š���������Դ���ã����������ϼ�ȱһ���ÿ�����������ѧ����Ⱥ�塰���˿��á��Ĵ�ģ�͡�
62�ڲ��������ģ��Ҳ�ܡ�С������
�����������Ȧ�������˷�����һ����������Դ��ģ�ͣ���Ӣ˫��Ի�ģ�� ChatGLM-6B����������ص�����������֧���ڵ������Ѽ��Կ��Ͻ��в�������ʹ�ã��������߱����˿��õĻ�������ǧ�ڹ��Ĵ�ģ��������Ҫ�ɰ���ǧ���Կ����ܲ���
ChatGLM-6B��������AI��ҹ�˾�������廪�����ɹ�ת��������2022��8�£�����AI���µ�ǧ�ڼ�����ģ��GLM-130B��Ӣ˫�����ģ����ʽ���о����ҵ�翪�š�����130B����130 billion����д����1300�ڲ������ݹ������ܳƣ�GLM-130B��BERT��GPT-3��T5���Ų�ͬ�ļܹ�����һ��������Ŀ�꺯�����Իع�Ԥѵ��ģ�ͣ�����˫��֧�֡��߾��ȺͿ������������ԡ�
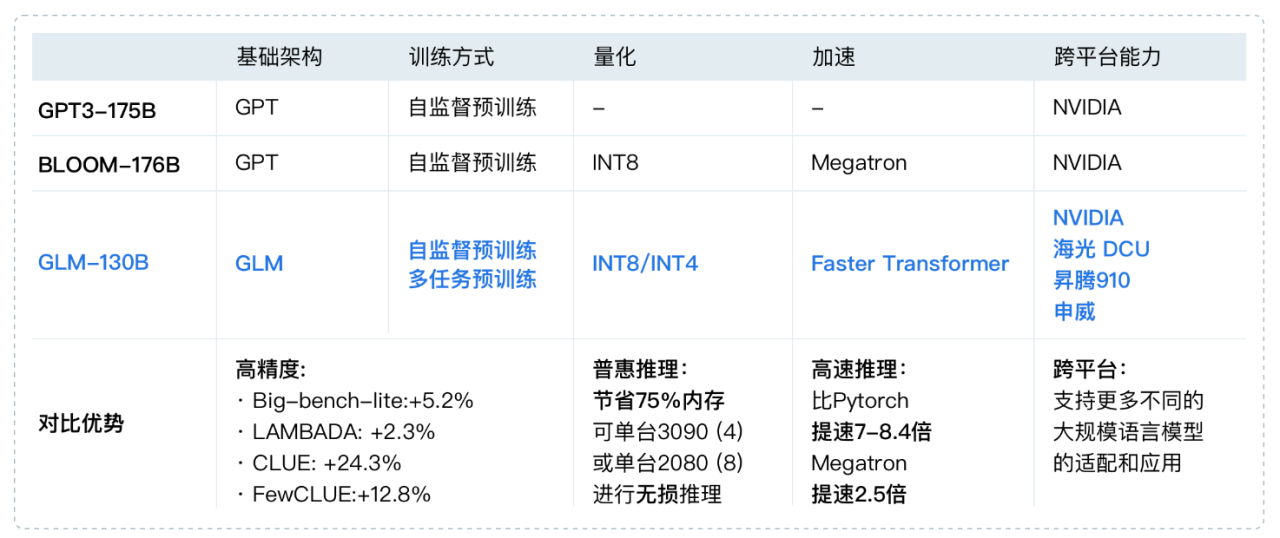
2022��11�£�˹̹����ѧ��ģ�����Ķ�ȫ��30��������ģ�ͽ�����ȫ��λ�����⣬GLM-130B ������Ψһ��ѡ�Ĵ�ģ�͡����� OpenAI���ȸ���ԡ�����Ӣΰ�����ĸ���ģ�ͶԱ��У����ⱨ����ʾ GLM-130B ��ȷ�ԺͶ�����ָ������ GPT-3 175B (davinci) �ӽ����ƽ��³���Ժ�У���������ǧ�ڹ�ģ�Ļ�����ģ�ͣ���Ϊ��ƽ�Աȣ�ֻ�Ա���ָ����ʾ��ģ�ͣ��б��ֲ�����

2023��3��14�գ�����AI����GLM-130B�Ƴ���ǧ�ڶԻ�ģ�� ChatGLM ��ʼ�ڲ⣬ChatGLM�Ա�ChatGPT���߱��ʴ�ͶԻ�������������Ľ������Ż���������������ʾ��߱�ChatGPT3.5����70%������ˮƽ��ͬһ�죬����AI����Դ��62�ڲ��� ��ChatGLM-6B ģ�͡����ݹٷ�Blog��ʾ��ChatGLM-6B ��ȡ��GLM-130Bһ���ļܹ��뼼�����佫��������ǧ�ھ���62�ڣ���������������
��һ�������������ģ������������ChatGLM-6B�������������INT4 �������������ֻ�� 6GB �Դ棬֧���ڵ������Ѽ��Կ��Ͻ��б��ز��𣬲����ż��������ɱ�������͡�
�ڶ�����Ӣ˫��Ի��������˳�ֵ���Ӣ˫��Ԥѵ��������Լ 1T ��ʶ������Ӣ˫��ѵ�������Լල���� �������������෴��ǿ��ѧϰ��ѵ����ʽ�������ܶ���������ͼ������ӵ�в��������ܱ��֡�
����������������GLM-130B�Թ����ſ���̬�нϺõ�֧�֣����ڹ����ĺ��� DCU����Ϊ�N�� 910 ��������������������Ӣΰ��оƬ�Ͻ���ѵ����������ChatGLM-6B��Ϊ������������������ģ��Ҳ֧���ſ�ƽ̨���������ҹ�AI�����ر��Ǵ�ģ����������
����ĿǰChatGPT������һ�ԡ�ͨ��ǧ�ʵ������ż����ܸߣ���ChatGLM-6B֧�ֹ������飨http://open.bigmodel.ai/trialcenter������ע�����������һ�������������Խ���AI��Ȧ�з�����Ŀ�ˮս�����ش�úܵ��壺
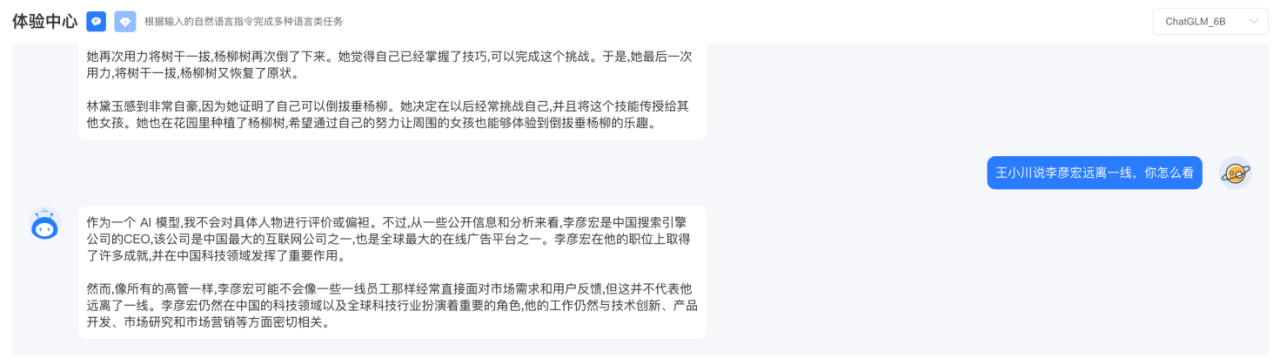
�Ҵ�����һ����Ϊ�����۵����ֻ�Mate X3�����⣬��ChatGLM-6B��æдһ����٣�����й��оأ�˼·û���⣺
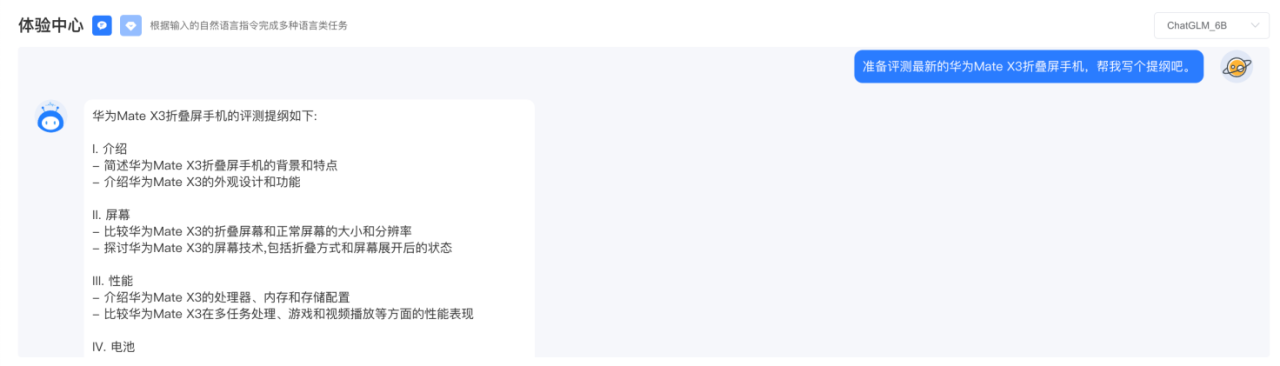
дʫ�����ij��������ڻ��£�
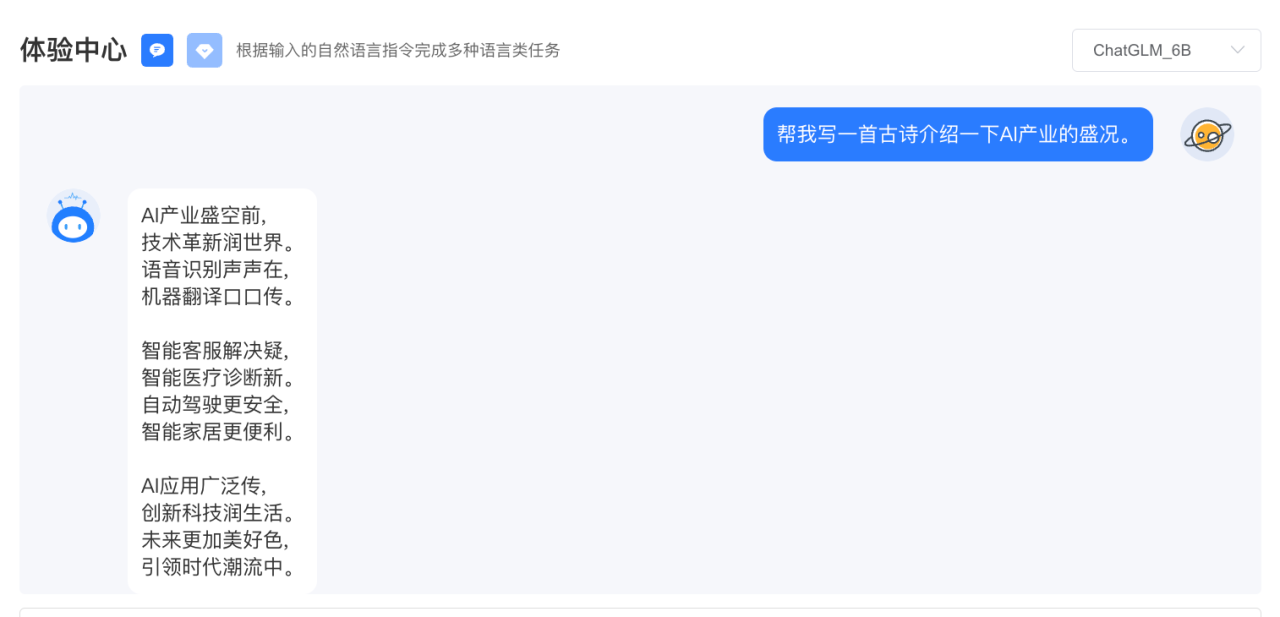
��ҵ�İ���������ȡ��������ʶ���������������ѩ������ǡ������д����ˣ�

�����д�ʱ��ChatGLM-6B�ı������ChatGPT������һ�ԡ�ͨ��ǧ�ʲ���ѷɫ�����ǵ�����һ��ֻ��62�ڲ����ġ������桱��ģ�ͣ����¡�ѷɫ��Ҳ������ԭ���ˡ��ر�ֵ��һ����ǣ�����AI���ȡ���⡢д���µȲ�ͬ���������˵��ţ������������ӦAIGC����ʱ�и���ɫ�ı��֣�
ChatGLM-6B�IJ������ֻ��62�ڣ����Ҳ����һЩ���ݻرܵ����⣬���������������ʵ��֪ʶ����ʱ���ܻ����ɲ���ȷ����Ϣ�����ó��������⣨����ѧ����̣��Ľ�𣬶Զ��ֶԻ���֧�ֺ�һ�㡣
Ҫ����ӵ���˵����̣�AI��ģ����Ȼ���ص�Զ��AI��ģ�͵������ƺ��ǡ�AIԤѵ����ģ�͡�����Ԥѵ������������˼���������⣺Ԥ��ѵ���ã�����Ӧ�ÿ����߿ɵõ�����ֳɵ�ѵ����������ڴ�ֱ�ӿ���AIӦ�ã�������Ҫ��0��1ѵ�����ݡ�����ģ�͡���ͨ���ѵ����ݼ���̰��ʽ����ѵ��ģʽ��ӵ�н�ǿ��ͨ���ԣ������Ͽɷ���������Ӧ�ó�������С�������������ļ���ʵ�֣������Ӧ�ÿ����߿��ٻ����乹������Ӧ�á�
�Զ�����ChatGLM-6B�ij������ֳ��˴�ģ��Ԥѵ���뷺��ͨ�õľ��裬���������ǡ�������еá�������һЩ�������������˲����ż����ÿ����ߡ��о����ڱ��ؼ�����Ͻ��д�ģ�͵���������ѵ�����˿��ܣ������ɸ��õ�֧�ִ�ģ����ص�����������
��ǰ�����һ�ι�����ϣ�����AI CEO����������һ���۵㣬��AIGC��ҵ������Ԥѵ����ģ�ͣ�ԭ�������������棺��һ��ͨ�÷���������ΪAI�з�������Ч�����Ƿdz��ؼ������ԣ��ڶ����������֪ʶ���ô�ģ���ܸ���ģ���˵����ܡ������ͬʱҲ������һЩ��ս������ɱ��߰���ѵ�����ݾ����ڳ��ȡ���ChatGLM-6B �Ŀ�Դ��������AIʵ��ͨ�÷���������AI�з��ż���ɱ���ʵ����
��Դһ���º�ChatGLM-6B ��Huggingface ȫ���������ѳ���75��������λ��Huggingface ȫ��ģ�����ư���ף�GitHub �DZ����ﵽ1.7��С��������ChatGLM-6B �ڿ�Դ���������Ǵ�ģ���ȵ���Ӱ��
ChatGLM-6B�ô�ģ�ͼ��������˿��á�
ChatGLM-6B ͨ����������ģʽʵ�ִ�ģ�͵�ͨ�÷���������˴�ģ�͡��߲����ʡ���һ�����ߵ�ʹ�㡣��������Ĵ�ģ�Ͳ�ҵ�У����Ŷ���ռλ��ChatGLM-6B����AI�����ջ��а�����Ҫ��ɫ��������˵����������ģ�Ͳ�ҵ�������ºô���
1�����ʹ�ģ��ʹ���ż���������߿����ɲ����ģ�ͣ�һ���棬 ChatGLM-6B�ǿ�Դ�ģ������߿������ģ�͵ײ�һ̽������ֻ�и������ģ�͵���ת���Ʋ��ܸ��õ����úô�ģ�ͼ�������һ���棬�����߿ɻ��� ChatGLM-6B�����ϲ�Ӧ�ô��£����������ǽ����붼�벻���Ĵ���AIӦ�ã��ڹ�ҵ�������л���GLM-130B������ǧ�ڼ���ģ���ϡ�
2�����ʹ�ģ�͵�ѵ���ɱ�����ģ��ѵ���ɱ��߰��Һ��ܣ����ڿ�Դ��ChatGLM-6B�������߲�����Ҫ��Ӵ��������ϵ����ѵ������ʱҲ����Ҫ�ķѾ��˵ĵ�����Դ������ʱ�����ڽ�������̣���������Ч����̼�����õ�Ӧ�ô�ģ�ͼ���������AI��ҵ����������
3�������ڴ�ģ�͵Ľ����ռ����Dz�˹������˵���˶�Ҫ���̣�δ��������Ҫѧ��ʹ��AI���ߡ��ڽ�����������������רҵ�Ĵ�ѧ���Լ��Ա������Ȥ�������ֻ꣬Ҫ��һ̨�����Կ��ļ�����������ɵز���ChatGLM-6B�����Ծ����˽Ⲣѧ��Ӧ�ô�ģ����һ����������
���˾��ã���ChatGLM-6B+GLM-130B�������ģʽ��AI��ģ�Ͳ�ҵ����ṩ��һ���µķ�ʽ����������ģ�Ͱ����ջݵĽ�ɫ���ø��������ɡ����š���ѧϰ�����⡢��Ϥ��ģ�ͼ��������д���Ӧ�õĿ�������֤�����Եȡ�����Ӧ�ýΣ����б�Ҫ��ʹ��GLM-130B������ǧ�ڼ���ҵ����ģ�Ͳ����Ʒ������ͻ����û��ṩ��ҵ������
����
AI��ģ�ͼ���������һ�ֲ�ҵ��������������������������������������ϵ���������¶��壬���ǵ������빤����ʽ����ҵ�ľ�Ӫģʽ�Լ�����������ʽ���ڱ��ع����������Ĵ����£�AI��ģ���ѳ�Ϊ����֮��������
�ڼ����˳�ӿ��ʱ�������������������ܣ�����������漤�ң��Ƽ��Ǻ��Ľ�������������ʮ����滮��Ҫ���Ƕ�ʮ�����ȷҪ��ǿ�Ƽ������������ã�ʵ�ָ�ˮƽ�Ƽ�������ǿ����������ʱ�������£���ģ�ͳ��˸�оƬһ�����Ƹߵ㣬�ҹ�����Ҫ���Լ��ĵײ��ģ�ͼ���������Ҫ���Լ��������Ĵ�ģ��Ӧ�����ҵ��̬��
�⼸�죬��С����ٶȵĿ�ˮս�ڴ�ģ����ҵ�������飬��ʵ���ۡ��ҹ���ģ�;���ChatGPT�IJ�྿����2���»���2�ꡱûʲô���壬�ҹ���ģ�ͼ�������GPT���п۵IJ�࣬�ƶ���ģ�ͼ��������Ͳ�ҵ��أ��Ǵ�ģ������ǵ����Σ���ҵ����ҪChatGLM-6B�����Ŀ���صĽ�������������������AI�����ż���δ�����ɽ�ϵʹ���ȼ���ʵ�֡����˶����ģ�Ϳ������������AI��ģ�ͼ����ջݵıؾ�֮·��Ҳ���ҹ�AI��ģ��ʵ�ָϳ��Ĺؼ���
�ڹٷ������ϣ�ChatGLM�Ŷ���һ�����ص����֣�
������һֱ��̽�������Ժ�Ŭ����GLM ϵ��ģ��ȡ����һ˿��չ������������ʶ����ģ���о��Ͳ�Ʒ������ OpenAI �� ChatGPT ����һ�� GPT ģ�ͣ����������Բ�ࡣ�й���ģ���о���ԭ���㷨��AI оƬ�Ͳ�ҵ�ϵ�����ͻ����Ҫ��ҵ�һ��Ŭ��������Ҫ���Ƕ���һ�� AI �˲ŵ�����������������˵��ǣ�GLM �Ŷ��ڹ�ȥ����̽���Ĺ����У���һȺ���黳�����������и�ֵ������˼������Dz�����ս�����ֿ��������һ���ǣ�һ��ҹ��һ��ɳ���һ���졣ͨ���˹�����̽��������һֱ��·�ϣ�Ŭ��ǰ�С���
�Ҿ��û��Ǻ����ĵġ���ģ���ȳ��У���ˮ���㡢���ȵ㡢�㳴������Ҳ��٣���Ҳ��һЩ��̤ʵ�ص��Ŷ������з���ģ�ͼ������뷽�跨���ƶ���ģ����أ�ֻ����Ϧ���������ߣ����ǣ�ֵ�ñ���
- ��Ȩ����
- ���Ľ��������߹۵㣬��������������������ϵ������Ȩ����ר��������δ�����ɣ�����ת�ء�



ɨһɨ����ʶ���ά��
��ע�������ٷ��Ź��ں�