����ֻҪ�Ǹ�AI�����йصĻ���Ʋ���һ�����⣺AI��ģ�͡�
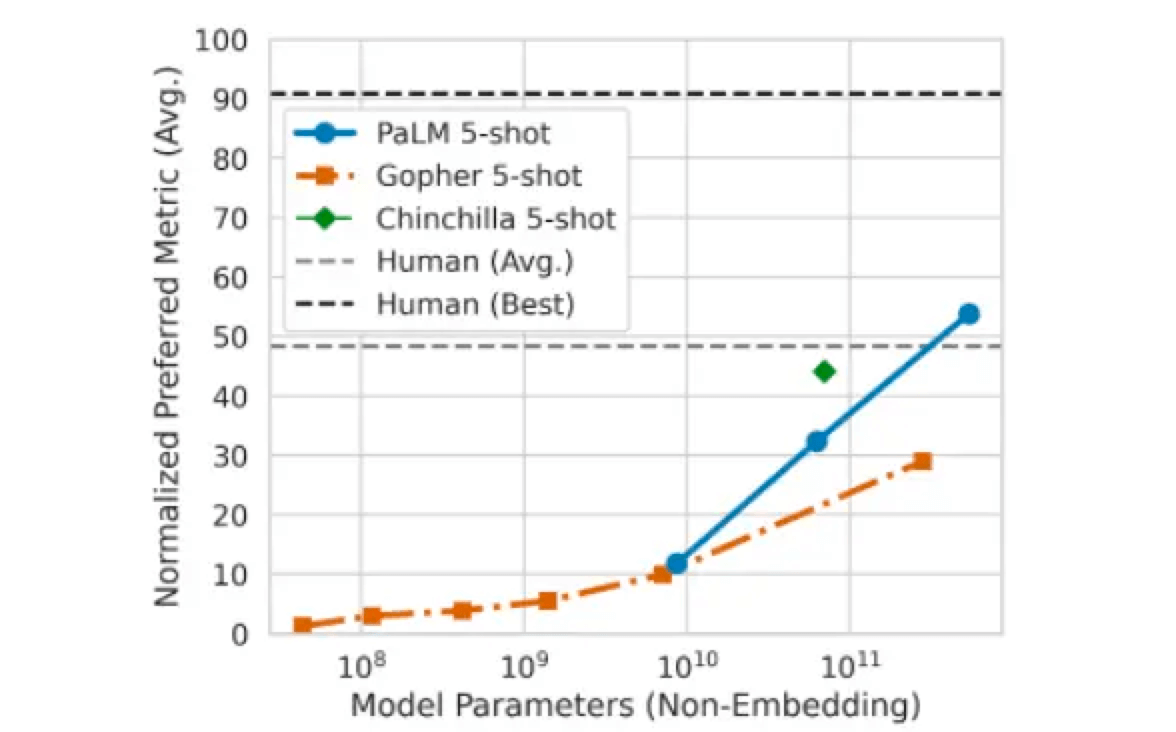
�ڸոս�����Google I/O����ϣ��ȸ�չʾ������ν����Ƚ���Ԥѵ����ģ��Ӧ�����ճ������У�����ȸ��ĵ����Զ��ܽṦ�ܿɽ���ʮҳ�ļ��ܽ�ɼ��仰���� 4 ���ύ�������йȸ��о���Աѵ����һ�� 5400 �ڲ����Ĵ�������ģ�͡���PaLM�������Զ����ɴ��롢�����ѧ���⡢�� bug������Ц���Ĺ���AlphaBet CEOɣ�����Ƥ������ʾPaLM���ŵ����ڿ����������ϵ�������������еĸ�����ϣ�������ѧ�����ϵ�ȷ�������� 58%���ӽ� 60% �� 9 �� 12 ���ͯ��������ˮƽ��
����AI��ͷ�ٶȲ��ض��ã�����2019����ѿ�ʼ����AIԤѵ��ģ�ͼ�����2021��12����ʽ������ȫ����֪ʶ��ǿǧ�ڴ�ģ������-�ٶȡ����ģ�������ģ2600�ڡ���5��20�յ�WAVE SUMMIT 2022���ѧϰ�����߷���ϣ��ٶȹ����˷ɽ����Ĵ�ģ������ȫ��ͼ�����֧�Ŵ�ģ�Ͳ�ҵ��ص�3���ؼ�·������ҵ������ҵ��ģ�͡����Ĵ�ģ����һ����ģ�ͼ������˵��ģ��IP����WAVE SUMMIT 2022�����Ĵ�ģ�ͼ���ӭ��ʮ���³�Ա�����ǻ������������ҵ�Ȳ�ͬ���ʹ�ģ�͡�

���ȸ�һ�����ٶ�Ҳ��AI��ģ�͵��ص���������ԡ�֪ʶ��ά�ȣ�������������AI��ͷ��������������һ��ͬ�����йأ���Ϊ�������汾�ʾ�����NLP��������֪ʶ��֪ʶ��AI���ںˣ����������������Ҳ��ΪAI�����Ĺؼ���ҡ�
��AI��ģ�����ĵIJ�ֻ�ǹȸ�Ͱٶȣ�2021����������Ӣΰ��ȸ裬���ڵ��˳�����Ϊ�Ͱ����Խ��Խ��Ƽ���ͷ���ڲ���AI��ģ�͡�2022��AI��ģ�;������������ң����г�ΪAI�����ؼ��������ơ�
������Ƽ���ͷ����AI��ģ��Ϊ�İ㣿
AI��ģ��ȷ�سƺ��ǡ�AIԤѵ����ģ�͡�����Ԥѵ����������˼���������⣺Ԥ��ѵ���ã�����Ӧ�ÿ����߿ɵõ�����ֳɵ�ѵ����������ڴ�ֱ�ӿ���AIӦ�ã�������Ҫ��0��1ѵ�����ݡ�����ģ�͡�
AI��ģ��ͨ���ѵ����ݼ���̰��ʽ����ѵ��ģʽ��ӵ�н�ǿ��ͨ���ԣ������Ͽɷ���������Ӧ�ó�������С�������������ļ���ʵ�֣������Ӧ�ÿ����߿��ٻ����乹������Ӧ�á�
AI��ģ�������ѧϰ��������ͻ�ƣ���һ����ǿ��AI������ͨ���ԡ�
���ѧϰ���ٷ�չʮ������AI�����ѱ��㷺Ӧ�á���Ϣ�����ڽ����ѳ�Ϊ������ת�Ļ�����ʩ��AI����Ҳ��������һ�Σ�Ҳ����AI��ҵ������AI��ҵ�������٣�AIҪ֧�Ÿ��ӹ㷺���ʵij�����Ҫ֧�Ÿ�������ӵ�AI��������Ҫʵ�ִ����˹����ܵ�ǿ�˹����ܵ�������������ͳѵ��ģʽ�Ѻ������㣬���С��������ݡ����������������㷨�����Ե�AI��ģ��������ʱ��
����˵��AI��ģ�ͱ��ʾ������ѧϰ�ġ���ǿ�桱��ͨ����ģ�͡���ι���������������ѧϰ�������������и�ǿ�����̶ܳȣ���������Ȼ���Դ����ϱ��ָ��ѡ��ٶȡ��ȸ�Ⱦ�ͷ��̽������������Ԥѵ����ģ�͵�NLP������Ч���ѳ�����ȥ��õĻ���ѧϰ������
AI��ģ����AI��ҵ���Ĺؼ���������Ϊ�ˣ�ȫ��Ƽ���ͷ��Լ��ͬ��עAI��ģ�͡�
2021��������³���CEO�����ǡ��ɵ�����ֱ�ԣ����ֽι�ע��һ���ص㷽����ǡ����ڳ�Ϊƽ̨�Ĵ��ģģ�ͣ����ִ���ģ�ͱ���ļ��㣬��μ�������ϵͳ��������Ϊ���ѧϰ�ڹ�ȥ20���10��ȡ�þ��չ����ģ��������һ��ֵ���ڴ��Ĵ��¼��������������ƽ��ľ�����������Ӣΰ�����Ϸ���Megatron-Turing��Ȼ��������ģ��(MT-NLG)��ӵ��5300�ڲ��������ơ����ްԡ����ٷ�����ͬʱ��õ���Transformer����ģ�ͽ硰��͡���ǿ�������ƺš�
��Ȼ��AI��ģ����Ȼ����һЩ��ȷ���ԣ�����Ҳ��ζ�Ÿ���Ŀ����ԡ�AI��ģ�����ջ����ʲô���ijɹ�����֪������������ǿ�˹����ܵ��ռ�ģʽ��Ҳ����ֻ�ǹ����ֶΣ�������Ŀǰ���Ѿ�Խ��Խ�����س��ֳ���������NLP������չ�ֳ����ۿɼ������ƣ������൱ǰ��������ӽ�ǿ�˹����ܵ�ѵ����ʽ�����ƽ�AI��֪����ͻ�ơ���ս�������ܵĹؼ���
AI��ģ��ٲȻ�ѳ�AI��ҵ�����ѧϰ��ĵڶ��������˳������ѧϰ������AI��ʵ����������ҵ����AI��ģ����չ�ֳ��ƶ�AI������ʽӦ������ҵ��������DZ����
�����ǰٶȴ�ʱ�˿̼���AI��ģ�͵�Ե�ʡ�
��Ϊȫ���������������粼��AI��������ҵ���ٶȲ����������AI���������̽����AI��ģ�ͼ����ٶ���2019������ڲ��֣���һ������WAVE SUMMIT �ϰٶ�CTO������ǰհ����������ѧϰ�ƶ��˹����ܽ��빤ҵ�������Ρ�����ȥ���꣬AI��ҵ���������ڱ�Ϊ��ʵ���ر�������������������ǻ������Ҵ����ƶ��������־��õ������£�AI��ҵ���������ڽ�һ�����٣����н���ǧ�а�ҵ��Ϊ��������һ���Ļ�����ʩ�����ơ�
AI ��ģ��������ʱ���ӱ���WAVE SUMMIT�����µ�����ȫ��ͼ�������ٶ��ڴ�ģ�Ͳ����ϳ���Ͷ����룬��������һ�����˲�ҵӦ�õĴ�ģ����ϵ��������ƽ̨��������̬�ٴ��£���ͬ��������һ����̫һ����·��

�ٶ�����AI��ģ�Ͳ���������ʲô��
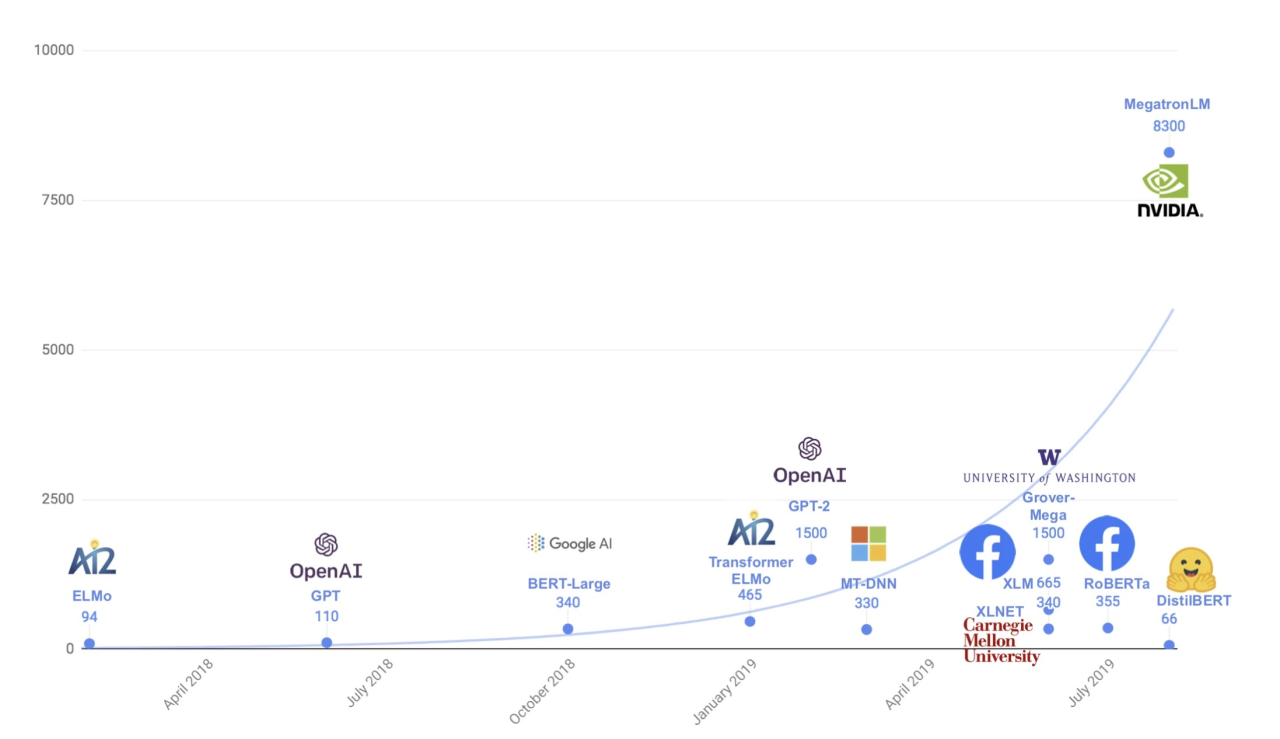
2018��ȸ跢����ӵ��3�ڲ�����BERTԤѵ��ģ�ͣ���ʽ����AI�Ĵ�ģ��ʱ�������������꣬��ģ�͵ġ���̨���ϣ���·��ս�߽������������ƴ�Ľ���һֱ��Χ�Ʋ�����
2019��OpenAI�Ƴ�NLP��ģ��GPT-2��ӵ��15�ڲ�����Ӣΰ������83�ڲ����������죨Megatron-LM�����ȸ��ַ�����110�ڲ�����T5��������170�ڲ�����ͼ��Turing-NLG��
2020��OpenAI�Ƴ�NLP��ģ��GPT-3��ӵ��1750�ڲ������״ν���ģ�Ͳ�����ģ������ǧ�ڼ����ƽ�������Ԫ���������ڴ�ͳ��NLP�����⣬��������������̡�дС˵��д����ժҪ��
2021���˳��Ƴ��ġ�Դ1.0��ӵ��2457�ڲ�������������ԽGPT-3���ȼ硰���ްԡ�MT-NLG��Դ1.0���������ݼ�ӵ�в��컯���ƣ��ʶ�ȫ������ģ������AI����ģ�ͣ�������д�Ի�����дС˵�����š�ʫ�衢������
2022��ոս����Ĺȸ�I/O����ϣ��ȸ蹫����PaLM ���Դ�ģ������ӵ��5400 �ڲ�����
�����Ӵ����ٵ���
Ȼ�����ٶ���WAVE SUMMIT 2022�Ϸ����ķɽ����Ĵ�ģ��ϵ��ȴû��ǿ�������������ٶȼ��Ÿ��ܲ�������Ϊ����������AI��ģ��ΨһҪ��ķ�����ص���ʵ�������ǹؼ����ٶ�����һ��������ʮ���ģ�ͣ���������ͬ�ȹ�ģ������������ǿ��Ч�����á�Ч�����ߣ��Դ�����һ������ı����������ĺ��ʣ��ں��ḻ����
��ǰ�ε�AI��ģ�;����������������������PK�����������е�ȭ����������ζ��ȭ����������Ȼ����Խ�ֵ�ѡ��Խ�������ɽ�����AI��ģ�Ͳ�һζ����������֡��������ڡ����ĺ��ʡ��������㹻���Ļ�����ǿ�����ḻ�ں�����������ں����ǡ�֪ʶ��������һ�����һ����
���ΰٶ����Ĵ�ģ����ϵһ���Է���10����ģ�ͣ����ǻ�����ģ�͡������ģ�ͺ���ҵ��ģ��������ϵ��û��һ����ģ��ǿ����������������ǿ������ҵ��֪ʶ��ǿ�������ԡ�
10��AI��ģ������ֵ�ù�ע�������ġ���ҵ��ģ�ͣ�������ҵ����ҵ��AI��ģ�͡��ٶȻ���ͨ������ѵ�������Ĵ�ģ�ͣ�������ҵӦ�ó����д�����������ҵ���еĴ����ݺ�֪ʶ�������ҵ��صĴ����㷨��ƣ��Ƴ���ҵ��ģ���ʺ��ڶ�Ӧ��ҵ����AI��ҵ��Ӧ�ã��������Ϲ��ҵ����з�֪ʶ��ǿ�ĵ�����ҵNLP��ģ����-�ٶȡ����ģ������ַ������з���֪ʶ��ǿ�Ľ�����ҵNLP��ģ���ַ�-�ٶȡ����ġ�

����������ҵ��ģ���⣬�ٶȻ����������Ļ�����ģ�ͺ������ģ��һ���˸����ں��������֪ʶ��ǧ��NLP��ģ��ERNIE 3.0 Zeus���������Ӿ�����ѧϰVIMER-UFO 2.0����Ʒͼ����������ѧϰVIMER-UMS���ĵ�ͼ�����ѧϰVIMER-StrucTexT 2.0������-���Կ�ģ̬��ģ��ERNIE-SAT������-���Կ�ģ̬��ģ��ERNIE-GeoL���Լ����������������Ļ��������ѧϰHELIX-GEM�͵����ʽṹ����HELIX-Fold��NLP��CV�Ӿ�����ģ̬��Щ�������ڸ��и�ҵ��Ҫ�õĻ���AI��ģ�ͣ��������-���Կ�ģ̬��ģ����Щ����������������
�Ӱٶ�����AI��ģ����ϵ������һ�°ٶ���AI��ģ�͵�˼·��
һ���棬����֪ʶ��ǿ��AI��ģ�͡�
AI��ģ�Ͷ���̰���س��š����ݼ�������ѵ�����ٶ�����AI��ģ��������ѡ���Եء���֪ʶ�������������ձ�ӵ�е�ͨʶ��֪ʶ���������������רҵ��֪ʶ�������ҵ����ҵ������֪ʶ��
ǿ��֪ʶ��ǿ��һ���棬������AI��ģ��ѧϰЧ�����á�Ч�ʸ��ߣ�������Ļ�˵���ǡ�֪ʶ��ǿ�����Ĵ�ģ�ͣ��������嵥Ԫѧϰ��ѧϰЧ�ʸ��ߡ�����һ���棬��AI��ģ����������ǿ�˹����ܡ�����AI��ģ�ͱ�ڸ��������϶�������ݶһ�������ر����ڲ�ȷ���ԡ���Ȼ������֪ȱ�ݣ�֪ʶ��ǿ���Թ�ܲ������⣬��Ϊ֪ʶ�Ǹ�����������ݣ������û������ܴӸ�֪����֪������
�������ʷ����Ϊ��֪�����������߳�������һ�θ�������֪�������ʲ���������������Ϊ����Ҳ�У����������������ڴ�����ӵ�л�ȡ���γ�֪ʶ���������ٲ��Ͻ�����
��2017���AI World �����˹����ܴ���ϣ��������̸��һ���۵㣺��֪ʶ���˹����ܵĻ�ʯ����������ģ��������Ӿ��������ȸ�֪�����������ָ�֪�������������ר��������Ҳ�߱���֪����������ijЩ��֪�����������ǿ�����繷�����������֪�������еģ������������������������������ͬʱ��֪ʶҲʹ�˲��ϵؽ��������ϵ�����������֪ʶ�����ƶ��˲��Ͻ�������Ҫ����������֪ʶ�����˹����ܵļ�ֵ�����ڣ��û����߱���֪������
�ٶ���AIһֱ���ӻ���֪ʶ��ǿ��ǿ��֪��AI�����������ѧϰ�����������ϵ��������Ӿ���NLP�����Ǹ��ϲ�������������AIӦ�ã������û��������嵽����������ʶ�����⣬�Ӹ�֪����֪��
��֪ʶ�û����߱���֪����������ͬ��������AI��ģ�͡�����ѧ�ҡ�����ʦ�Ǹ�AI��ģ����ι�IJ���ֻ��ԭ�����ݶ��Ǹ���֪ʶʱ��AI��ģ�;Ϳ����û����߱�����һ������֪������
AI��ģ�͵�֪ʶ��ǿ�Ȳ�������������Ҫ���Ⲣ�������⡣��Ԫ������ͨ���붯�����������һ���Ĺ�ϵ����Ҳ�����ԣ����������Ĵ�����Լ5ǧ�ˣ�����2570�ڸ���Ԫ��Զ�����ԣ�Լ1.4ǧ�ˣ�Լ860�ڸ���Ԫ����������ӵ����������������Ԫ�����Ƕ���9�����ԣ���������ϵͳ�������д����е���Ԫ����������5�ڸ������а��ݡ����봦�����������Ծ�ӵ��2�ڸ���Ԫ�����ಿ�־ͷ�ɢ�ڸ��������ԡ���
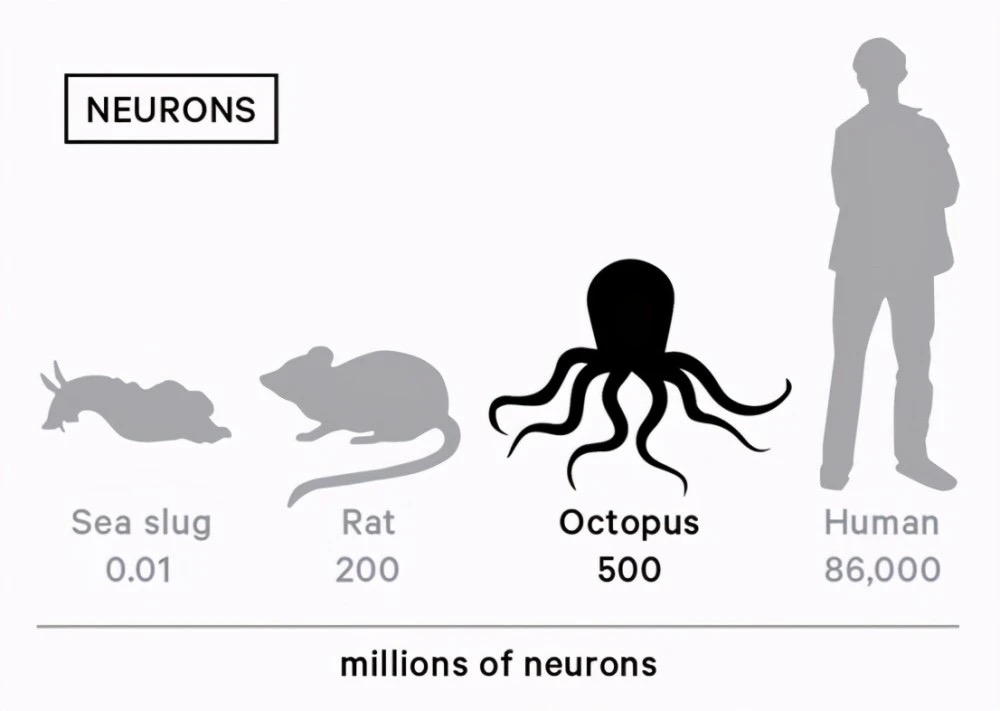
2020��������NLP��ģ��GPT-3ӵ��1750�ڲ������ѱƽ�������Ԫ���������������֪ʶ��ǿ��AI��ģ�Ͳ�������һ��������Ҳ�����ܱ����������
AI��ģ���ٵ�����ƴ������ԶԶ��������������������İٶȾ������ڲ����������ھ���������ÿһ�����Ĵ�ģ��ӵ�и�ǿ��֪ʶ������ǧ�ڹ�ģ������NLP������ģ��ERNIE 3.0 Zeus��ѧϰ�������ݺ�֪ʶ�Ļ����ϣ���һ��ѧϰ�����ֲ�ͬ��ʽ������֪ʶ����ǿģ��Ч�����ںϲ�λ���ʾ��Ԥѵ�������õؽ�ģ��ͬ����Ĺ��������ԣ�����ͬ������֯��ͳһ����Ȼ������ʽ��ͳһ��ģ��ǿģ�͵ķ��������������������NLP��ģ���ڸ���NLP�����ϱ��ֳ��˸�ǿ����������С����ѧϰ������Ҳ����˵��ERNIE 3.0 Zeus���ܲ��Dz�����ģ����NLP��ģ�ͣ���ȴ�Ǹ���֪ʶ������������ġ�ǿ��֪ʶ��ǿ�����Dz�����ģ��AI��ģ����ң�����Ҳֻ�аٶȡ�
��һ���棬���ҵ������Ƚ�ϵ�AI��ģ�͡�
�ٶ�����AI��ģ�͵ġ���ҵ����Ҫһ��Ϊ���ؿ���
һ�����ǰٶ�����AI��ģ����֪ʶ��ǿ���������Ӳ�ҵ������ص�֪ʶ���룻��һ����ٶ�����AI��ģ����ʵ��Ӧ���н�ϲ�ҵ������Ӧ�����ԣ����ҵ�����ٮٮ���������ҵ������ַ����к�����ͨ�������ҵ���ݡ�֪ʶ���㷨������Ե��Ƴ���ҵAI��ģ�͡�
��Ȼ���ٶ����ĵ���ҵ��ģ���������ģ�Ͳ��ǹ����ģ����߸�ǰ���ṩ�����������ַ�-�ٶȡ�����ģ�;�ʹ���˻���ͨ�����Ĵ�ģ�͵���ҵ֪ʶ�ھ������Ӻ����������ھ������ص����ϣ������ַ�ҵ���Ĵ��ģ�ޱ�ע��������ѵ����ѵ��������˲Ʊ������б𡢽��ڿͷ��ʴ�ƥ����㷨����Ԥѵ��������ģ��ѧϰ��������ҵ����֪ʶ��
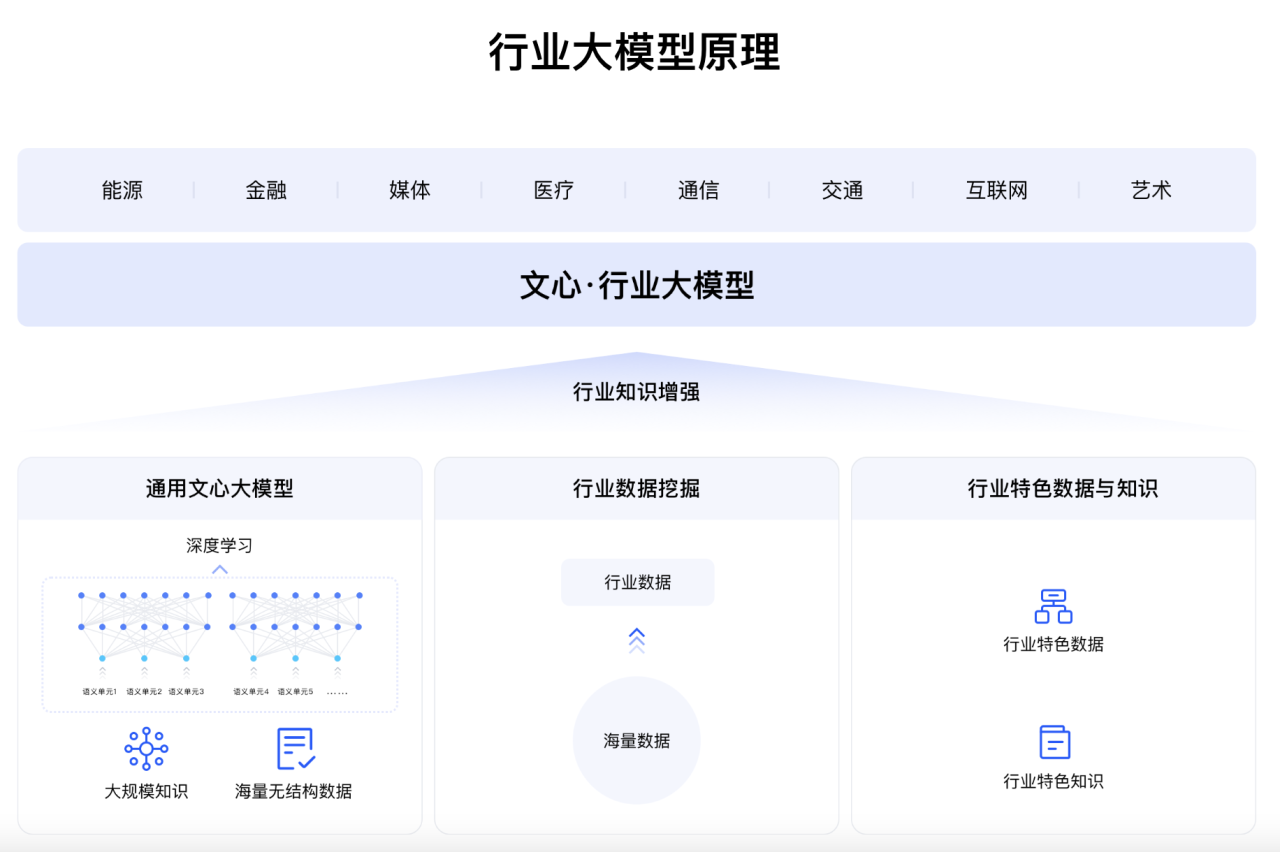
��������ͨ��+����+��ҵ��ϵ�����ģ����ϵ���������ڲ�ҵ����������ɫ��AI��ģ��ʵ�����������ٶ�����Ҳ���л����Ϊǧ�а�ҵAI��ҵ���������Ļ�����ʩ��
ǿ��֪ʶ��ǿ�Ͳ�ҵ��ϣ��ðٶ�AI��ģ�ͳ�Ϊҵ��Ψһ�ġ���ҵ��֪ʶ��ǿ��AI��ģ�ͣ���Ҳ��ζ�Űٶ�AI��ģ�Ͳ���Ҫ���ڲ����ϡ��ھ�����
�ٶ����ȴ����ھ�������Ϊ�ٶ�������ҵ�����Ƹ����Ĵ�ģ������֪ʶ��ǿ�������Ļ�����C��ҵ���ϣ��ٶ��к�����AIӦ�ó��������ṩ֪ʶ���롣2019��3������ERNIE1.0���������������ٶ�ȫϵ�в�Ʒ������ʹ�÷ɽ����Ĵ�ģ�ͣ����ڰٶ���������Ϣ������������Ȼ�������Ʒ���ڴ��ģӦ�����Ĵ�ģ�ͣ����Ĵ�ģ�����������˰ٶȲ�Ʒ���û����顣B��ҵ���ϣ����аٶ������ơ��ٶȷɽ��Ȱٶ�AI���Ÿ����и�ҵ�����Ĵ�ģ�Ͷ����վ��������ѳ�����ǧ��Ρ��ڸ����ҵ�����ೡ���������Ʒ��ʹ�ã��ٶ����Ĵ�ģ�;Ϳ��Ի�ȡ����֪ʶ������ʵ�ֲ�ҵ��֪ʶ��ǿ��
��ص�Ӧ�ó������Ǵ�ģ������ǵ�ͷ�ȴ���
�������Ǵ�ģ�Ͳ�ҵ��صĹؼ��ꡣ���ڷ��������ֱ�ԣ���Ҫ������أ���Ҫ����Ĺؼ������ǣ�ǰ�صĴ�ģ�ͼ����������ʵ�����ķ�������Ҫ����ƥ�䡣�����������֧�Ŵ�ģ�Ͳ�ҵ��ص�3���ؼ�·������������䳡������Ĵ�ģ����ϵ���ṩȫ����֧��Ӧ����صĹ��ߺͷ�����Ӫ�켤�����µĿ�����̬������WAVE SUMMIT 2022�Ϲ����İٶ����Ĵ�ģ�͵Ķ���������Χ�����������ؼ�·����
��AI��ģ������ʵ�������������ƥ�䣬�ÿ����߿��Ը����ż�������Ч�ʡ����ͳɱ���Ӧ��AI��ģ�ͣ���AI��ģ�ʹӾ�ͷ�IJ�����Ϸ��Ϊ��ҵ���ջݼ������ǰٶ���������Ŭ���������顣
���˶��صĴ�ģ����ϵ�⣬�ٶ������ṩ������ؼ���������AI��ģ����Ӧ�ó�������أ�
һ����ȫ����֧��AI��ģ��Ӧ����صĹ��ߺͷ�����
AI��ģ����AI��ҵ��������������ѧϰ���������˶��ɲ����з�̽���������С��������ݡ������㷨�� ��������������������AI��ģ��ȴ�����ż��ܸߵļ�������������һ����ģ����Ҫ�������ݡ����������ͺ����з�����Ǯ��ʱ�䡢����Ͷ��ͬ�����������������������������˼�ֵ10����Ԫ�ij����������ѵ����AI��ģ�ͣ�����˵ֻ�пƼ���ͷ����ʵ���з����Թ�ҵ����AI��ģ�͡�
�Ƽ���ͷ�з��ٿ��Ÿ����и�ҵ�Ŀ�������AI��ģ�͵���ط�ʽ��Ȼ�����ڷǾ�ͷ��������˵��AI��ģ�͵�Ӧ���ż������ѧϰ�ߵöࡣ����ÿ����߿��Կ��١���Ч����Ӧ��AI��ģ����ҵ�����⡣��Դˣ��ٶ����зɽ��������AI�����ߵ������뾭�飬�ڹ��ߺͷ������¹���
�ɽ����ҹ��������з������ܷḻ����Դ���ŵIJ�ҵ�����ѧϰƽ̨�������ѧϰƽ̨�������ߺͷ��������Ŷ���ķḻ���ۣ�����ѵ���������Ȼ��ڡ���Կ�����ʹ�����Ĵ�ģ�͵ij������ٶ����ⷢ����һϵ�д�ģ�Ϳ���������ģ��API�ͼ������Ĵ�ģ�͵ķɽ���ҵ��EasyDL��BML����ƽ̨������ͬ���͵Ŀ����ߣ�ȫ���ͷŴ�ģ�͵�ʹ��Ч�ܣ���һ������Ӧ���ż���
��˵���ٶ����IJ�ֻ���и�ǿ��AI��ģ�ͣ�Ҳ�и������������߰�������������Ӧ�á�����EasyDL��BMLƽ̨�����ۼƳ���1���������������Ĵ�ģ�Ϳ�������������3�������Ӧ�õ����ͨ·Ѳ�졢�㲿��覴ü�⡢ũҵ���溦ʶ��������Ѷ�����ȴ��������С�
��һ�������ṩӦ�ý����Ĵ�����̬ƽ̨��
�κα������Ҫ�ռ�Ӧ�ö��벻�����ٵĿ��������������ṩ�ĵ����Ϸ����������������ȹ��ܣ�����Ӫ����������Ĵ��»�����AI��ģ������ڷ�չ20��������ѧϰ������˵���µļ�����ϵ������Ӧ������˵������϶��Ƚ��ѷ�����ͬ������Ӧ�ð������Ƚ�ϡȱ����Դˣ��ٶ����Ĵ�ģ���ڷɽ���̬�¹���AI��ģ����̬���Ƴ��˻������Ĵ�ģ�͵Ĵ��������������ġ��D���������ø����û��������ܵ����Ĵ�ģ�͵�������Ӧ�ô���DZ�����ŷ���������������������
�ӡ�����������֪ʶ���IJ�ҵ��֪ʶ��ǿ�Ĵ�ģ����ϵ�������зɽ���ȫ���̵Ĺ��ߡ��������Լ�������̬�����ܿ����ٶ����Ķ���AI��ģ�͵�Ŭ����������ֻ��һ������AI��ģ�Ͳ����Ǿ�ͷ�ż��ľ������������dz�Ϊʵʵ������ص���ҵ������AI������ʩ�����ս��û����߱���֪���ܣ�ʵ��AI��ҵ�����������ò�ҵAI������ֻ�ǿںš�
�ٶ�����AI���������ʮ�꣬��Ҳ�ǹ������粼���˹����ܵ���ҵ�������ܿɹ���ǣ�������Щ��Ƽ���ҵ�������ϱ�Ǩ�����ٶ�ȴһֱ������AI��һ���������עAI�����з�������оƬ�����ѧϰƽ̨��AI��ģ�͡�AIӦ�ü�����ȫջAI��������һ���棬��������AI�����������ų������ٶ�������Ϊ�����ƶ���ҵʵ�����ֻ������ܻ�������
���ٲ�ҵAI�����ƶ�AI��ҵ����������AI��Ϊ����������������Ϣ�Ƽ�һ������������ʩ�ǰٶȵ���Ը��AI��ģ�͡��ɽ����ٶ������Ƶȶ��ǰٶ�ʵ��Ը���Ĺ��ߡ�������Ϊ�ٶȵ��ռ�Ŀ����AI��ҵ������������˰ٶ���AI��ģ��Ҫǿ������ҵ��֪ʶ��ǿ������ƴ����ƴ��ء��ٶȵ�ѡ��Ҳ����ΪAI��ģ������ǵĹ�ͬ����
���죬AI��ģ��ƴ�����ľ�������ʱ�������ˣ�����ע��ҵ���������ʱ����ʽ���١�
- ��Ȩ����
- ���Ľ��������߹۵㣬��������������������ϵ������Ȩ����ר��������δ�����ɣ�����ת�ء�



ɨһɨ����ʶ���ά��
��ע�������ٷ��Ź��ں�